diffusion model: backgrounds
20221210 suyako diffusion model
evaluation metrics
-
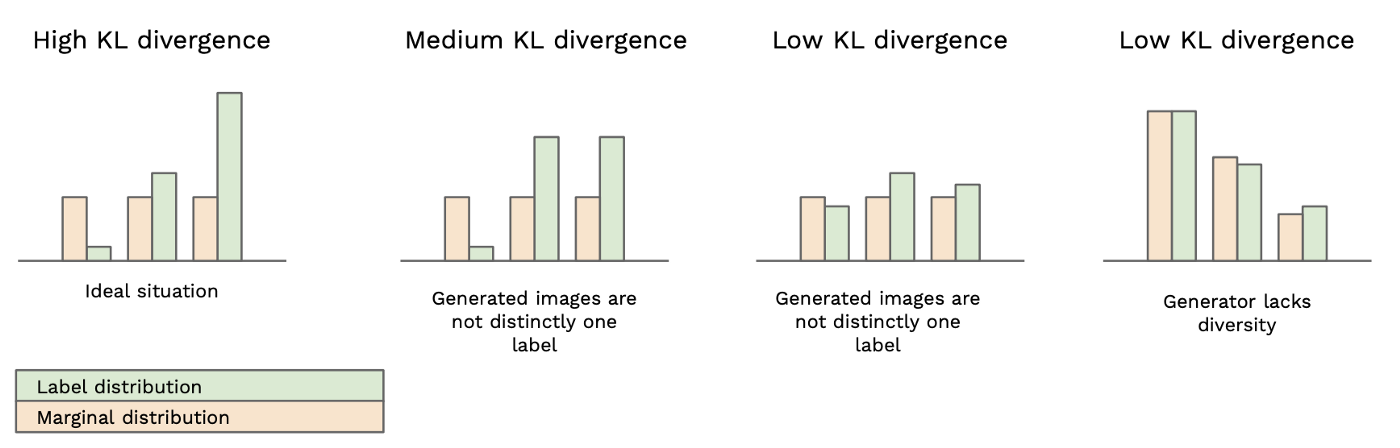
inception scores
-
the entropy of the distribution of labels predicted by the Inceptionv3 model for the generated images is minimized
- the predictions of the classification model are evenly distributed across all possible labels
- FID
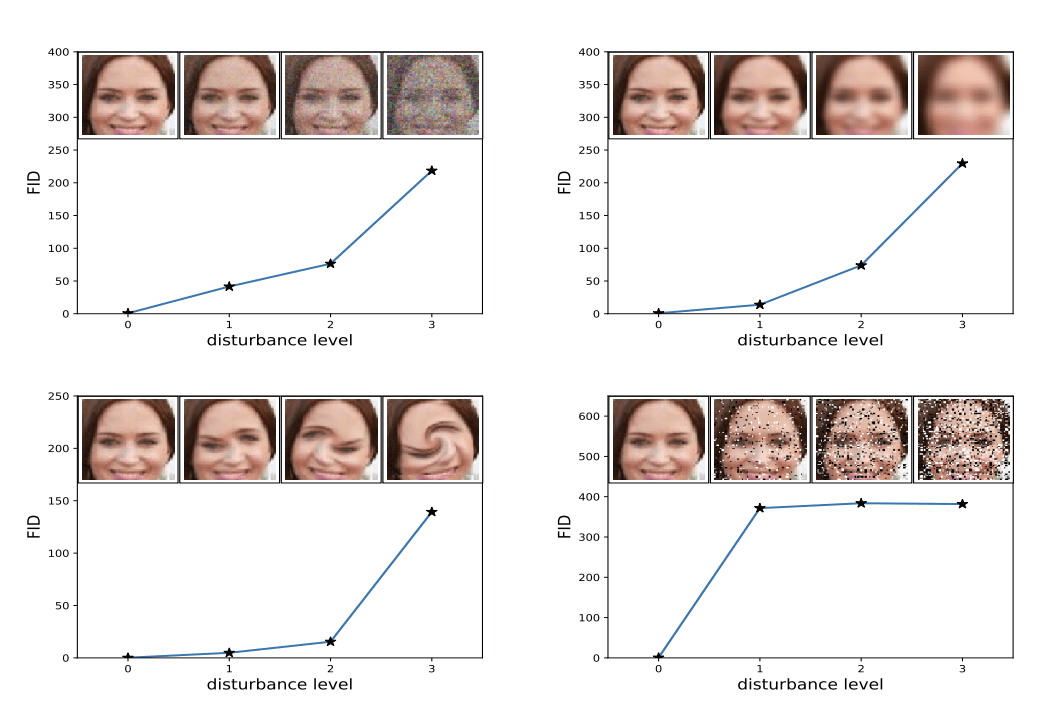
a performance metric that calculates the distance between the feature vectors of real images and the feature vectors of fake images(minimum distance to transport one distribution into another distribution)
DDPM
forward process
Given a data point sampled from a real data distribution , define a forward diffusion process in which we add small amount of Gaussian noise to the sample in steps, producing a sequence of noisy samples . The step sizes are controlled by a variance schedule . The data sample gradually loses its distinguishable features as the step becomes larger. Eventually when , is equivalent to an isotropic Gaussian distribution.
reparmeterization
Let and when ,
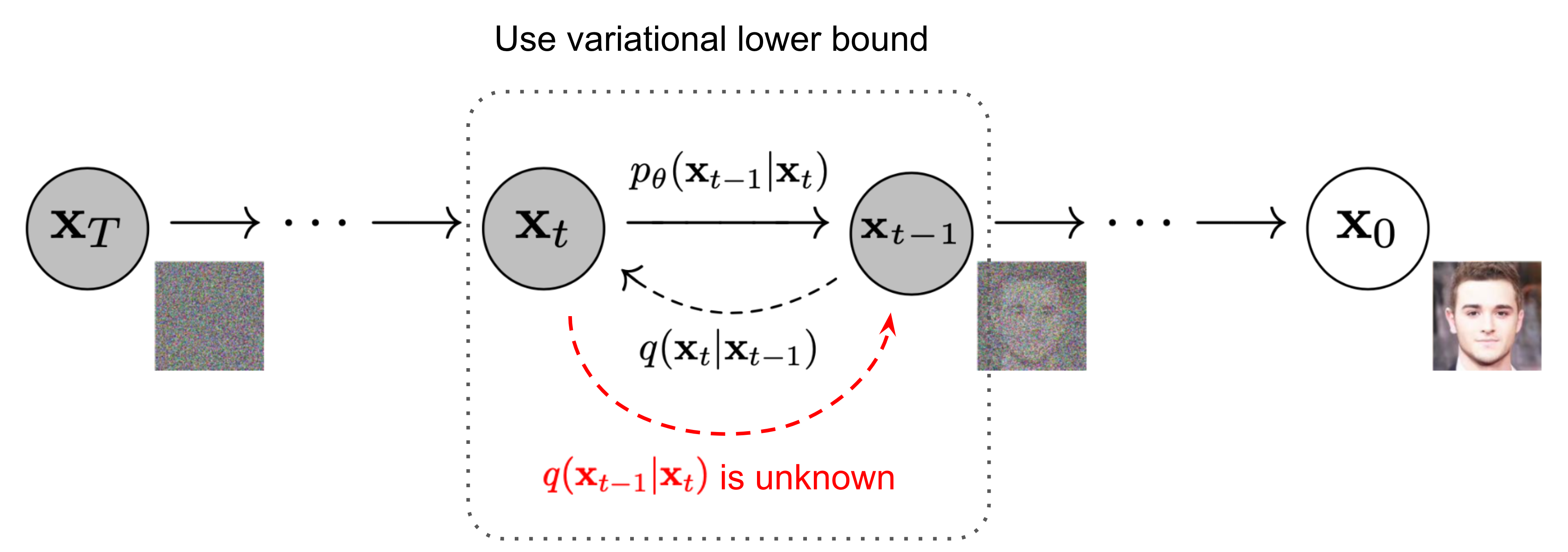
reverse process
if is small, will also be Guassian, however it's not easily estimate, therefore we need to learn a model to approximate these conditional probabilities:
It is noteworthy that the reverse conditional probability is tractable when conditioned on : following the standard Gaussian density function, the mean and variance can be parameterized as follows:
loss
variational lower bound the objective can be further rewritten to be a combination of several KL-divergence and entropy terms is a constant during training since are fixed, compares two Gaussian distributions and can be computed in closed form, which can be greatly simplified conditioned on setting to untrained time dependent constants( or ): modeled by a seperate discrete decoder derived from a Guassion distribution
simplified loss
it beneficial to sample quality (and simpler to train) on the following variant The case corresponds to approximated by the Gaussian probability density function times the bin width, ignoring and edge effects
The cases correspond to an unweighted version of , usually down-weight loss terms corresponding to small where amounts of noise is small
training and sampling
| training | sampling |
|---|---|
| 1: repeat 2: 3: 4: 5: Take gradient descent step on 6: until converged |
1: 2: for do 3: if , else 4: 5: end for 6: return |
NCSN
introduction
In order to build a generative model, we first need a way to represent a probability distribution. One such way, as in likelihood-based models, is to directly model the probability density function(p.d.f). We can define a p.d.f via:
here is always an intractable quantity for any general , which makes the gradient solution difficult. However, we can sidestep this difficulty by modeling the score function instead of the density function
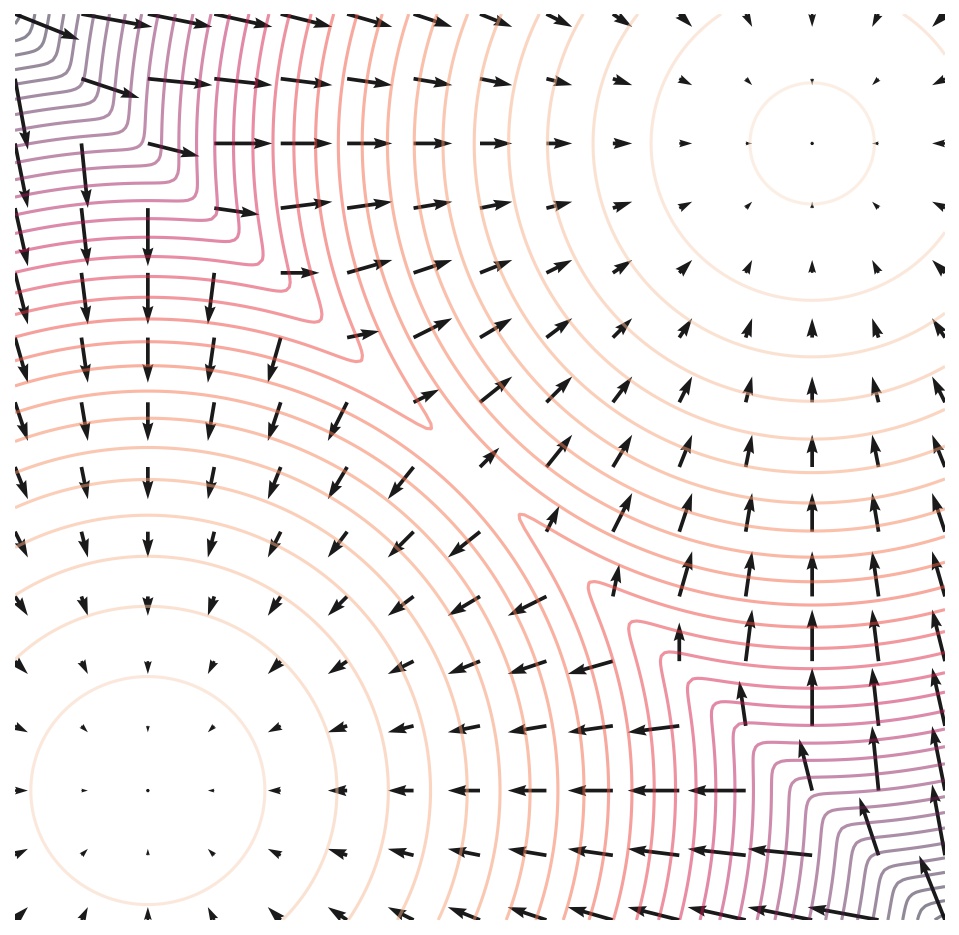
Langevin dynamics
Langevin dynamics provides an MCMC procedure to sample from a distribution using only its score function . Specifically, it initializes the chain from an arbitrary prior distribution , and then iterates following: When and , from this procedure converges to a sample from under some regularity conditions. In practice, the error is negligible when is sufficiently small and is sufficiently large.
manifold hypothesis
TODO
low data density regions
- inaccurate score estimation with score matching
In regions of low data density, score matching may not have enough evidence to estimate score functions accurately, due to the lack of data samples.
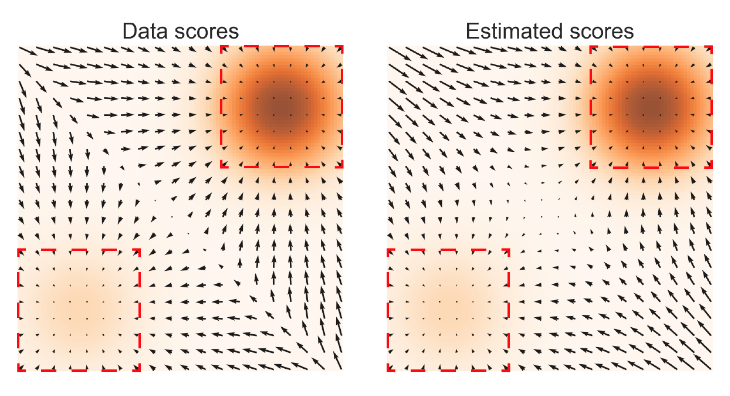
- slow mixing of Langevin dynamics
Consider a mixture distribution , where and are normalized distributions with disjoint supports. In this case, the score doesn't depend on . In practice, this analysis also holds when different modes have approximately disjoint supports—they may share the same support but be connected by regions of small data density. Now, Langevin dynamics can produce correct samples in theory, but may require a very small step size and a very large number of steps to mix.
multiple noise perturbations
In order to bypass the difficulty of accurate score estimation in regions of low data density, it's natural to pertube data points with noise and train score-based models on the noisy data points instead. However, larger noise can obviously cover more low density regions for better score estimation though alters the data significantly from the original distribution; smaller noise causes less corruption of the original data distribution, but does not cover the low density regions.
To achieve the best of both worlds, NCSN use multiple scales of noise perturbations simultaneously. Suppose there be a total of steps with increasing standard deviations , the th noise-perturbed distribution follow:

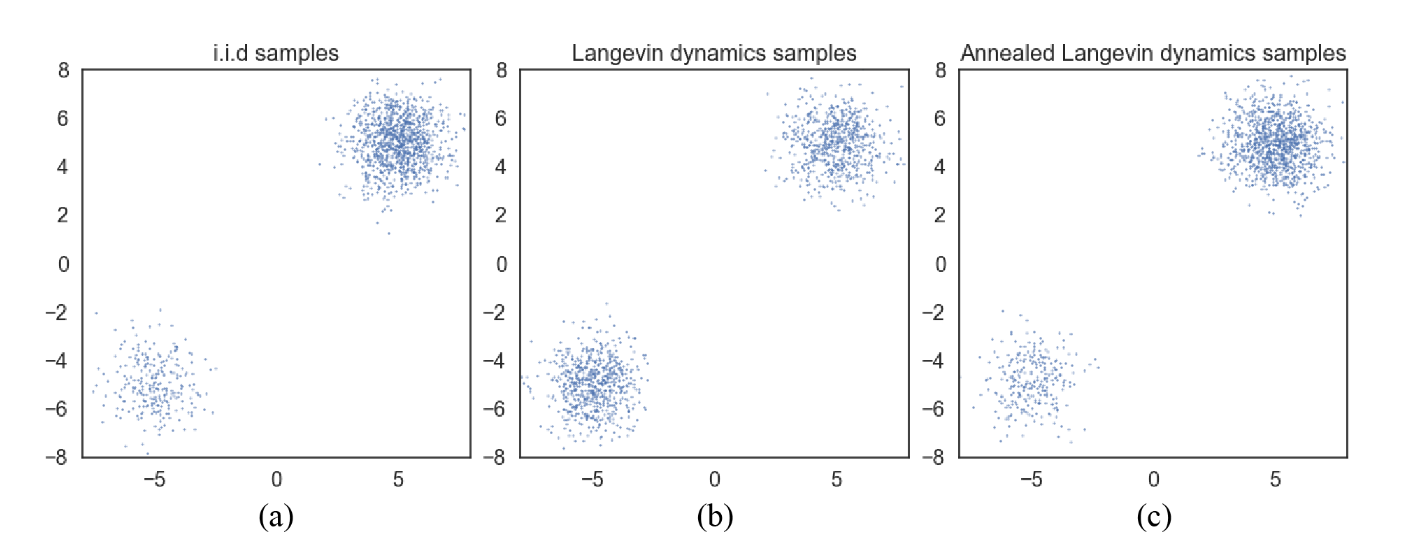
The training objective is a weighted sum of Fisher divergences for all noise scales: After training , samples could be produced from it by running Langevin dynamics for in sequence, which called annealed Langevin dynamic for the gradually decreased noise scale .
learning NCSN via score matching
similarities and differences between DDPM with NCSN
differences
TODO
similarities
- the schedule of increasing noise levels in NCSN resembles the forward diffusion process in DDPM. If we use the diffusion process procedure, and recall that , we can get
guided diffusion
In addition to employing well designed architectures, GANs for conditional image synthesis make heavy use of class labels. This often takes the form of class-conditional normalization statistics as well as discriminators with heads that are explicitly designed to behave like classifiers .
Given this observation for GANs, it makes sense to explore different ways to condition diffusion models on class labels. Guided diffusion exploiting a classifier to improve a diffusion generator, wherein a pre-trained diffusion model can be conditioned using the gradients of a classifier. In particular, we can train a classifier on noisy images , and then use gradients to guide the diffusion sampling process towards an arbitrary class label .
To condition an unconditional reverse noising process on a label , it suffices to sample each transition according to recall and approximate as follow We have thus found that the conditional transition operator can be approximated by a Gaussian similar to the unconditional transition operator, but with its mean shifted by . The final sampling algorithm like:
